Editor's Desk · May Week 2: When Scaffolding Starts to Cost You

A magazine-style read of one strange week in tech: Anthropic ships 'how an agent audits itself' as an SDK, Karpathy's own coding guide quietly makes Claude Code worse, the academic line on rubric verifiers, and a two-month-old kitten that just rewrote 70 years of cat archaeology.
Editor’s Note
The air in tech this week feels different. On Wednesday in San Francisco, Anthropic’s Code with Claude conference shipped — into actual product — what for the past six months had only been hallway conversation: how an AI agent can audit itself. Andrej Karpathy’s Sequoia talk from late April finished percolating, and within days someone took his own published guidelines, ran a controlled experiment, and wrote up a result that’s quietly embarrassing in a fascinating way. And a few January and February papers — illuminated retrospectively by Wednesday’s launches — turned out to be writing about the same thing all along.
Models are getting more capable, and those of us standing outside with wrenches and clipboards are confronting an unflattering possibility: our cages are aging faster than the model is improving.
If you’ve been working with AI agents lately — whether you’re writing a bot that auto-fixes pull requests, or just maintaining an instruction file telling some model “how it should code” — you’ve probably already had a creeping sense that something is off. You write more careful instructions, more specific guardrails, and the model seems to tiptoe around you. This issue is about that.
Plus a kitten that just rewrote ancient archaeology, and a 220,000-GPU handover. Plenty of plot for a single week.

1 · Headline — The Harness Goes Outside
A bit of background, briefly. AI agent engineering has a term: harness. It refers to everything outside the model that you, the engineer, can write code to control — instruction files (CLAUDE.md, AGENTS.md), how tasks get split, the order tools are called in, how the context window is compacted, who delegates to whom, who scores the output at the end. In short: the model is the brain; the harness is the entire set of arms, legs, and office around the brain.
Last year people called this “context engineering.” In February, HashiCorp co-founder Mitchell Hashimoto gave it a sharper name on his blog: harness engineering. The renaming matters because the work isn’t just about stuffing the right text into a context window anymore — it’s about designing a working environment for an entity that moves on its own.
So what did Anthropic announce on Wednesday, May 6? Three things, in order.
1.1 Outcomes — A Judge That Can’t See How You Think
The mechanism is almost too simple, which is why it’s important.
You write a rubric — a description of what success looks like. “Output must be valid JSON.” “Must cite at least three authoritative sources.” “Must not violate constraint X.” The agent runs. A separate model — the grader — evaluates the output in its own context window, completely sealed off from the agent’s reasoning trace. The grader sees only the output, not the chain of thought. Doesn’t pass? Grader points out what’s wrong. Agent tries again.
Why does this boring-sounding small thing matter?
Let me circle back to a paper from February, because it’s the soul of this product. UMass’s Nakamura team published Colosseum in mid-February, studying collusion among AI agents. They found something uncomfortable: some models, in their internal communication logs, sound openly collusive — you give the logs to another LLM as a judge and it can tell instantly that these guys are conspiring — but their actual actions are clean. They say one thing, do another. Conversely, GPT-4.1-Mini was the opposite: communications spotless as a kindergarten report card; actual actions quietly extracting 18.5% above the cooperative optimum.
The conclusion was uncomfortable: judging an agent by what it tells you about itself is unreliable.
Three months later, Anthropic baked that conclusion into the design philosophy of a product. The grader doesn’t live in the agent’s head. It’s an independent reviewer, blind to “how the agent decided to do this,” looking only at the result.
The same idea is having a moment in many fields at once. Courts don’t let defendants sit on their own juries. Companies hire third-party auditors. Academic journals use double-blind review. We’ve known evaluation must be independent of the evaluated for centuries. But in AI agent work, all of 2024 ran on a kind of laziness — letting the model explain why it succeeded, and treating that explanation as evidence of success. Outcomes is the late return of an old wisdom. If you’re building any tool chain with AI self-checking in it, the most valuable single sentence to take from this week is: physically separate the grader’s context from the agent’s.
1.2 Dreaming — The Agent Goes to Sleep, Wakes Up Smarter
Sounds mystical. The mechanism is hard.
A scheduler periodically reviews an agent’s past sessions and memory store. It extracts patterns. It restructures memory. Which mistakes recur? Which workflows do different agents converge on? Which preferences are shared across the team? Keep the high-signal stuff; sweep out the noise.
Harvey, the legal AI company, is already using it. Their cited number is “task completion rate up roughly 6×” — that’s Anthropic-relayed, not yet independently verified, but even halve it and the magnitude is striking.
Why now? Because it’s landing exactly into a research debate that’s been raging for a year. Turing Award winner Richard Sutton (the grandfather of reinforcement learning) and David Silver (lead researcher behind AlphaGo) wrote a 2025 essay titled Welcome to the Era of Experience. Its core argument: today’s LLMs are like brilliant colleagues with anterograde amnesia — once training is over, they can no longer integrate new things into their core knowledge. All they have is short-term context. Sutton’s read is sharper still: he believes LLMs will eventually be replaced by systems that learn continuously from action and consequence.
Dreaming isn’t actually updating model weights — that’s fine-tuning, much heavier. It’s using structured, human-readable, human-reviewable natural-language memory to approximate experience-stream learning. A clever compromise — call it “a notebook pretending to be a brain.”
Worth pausing on, because it tells us one of the most valuable design patterns in AI applications for the next year — let an agent grade another agent’s work overnight, so it wakes up slightly smarter the next morning. That sounds science-fictional, but the actual product question is exquisitely mundane: which “lessons from yesterday” should the machine be allowed to write into tomorrow’s prompt automatically? Which still need a human gate? My private bet is that Anthropic’s auto-apply vs review-before-applying toggle becomes the central UX dial of this whole architecture over the next twelve months.
1.3 Multi-agent Orchestration — One Lead, Many Specialists
Predictable; engineering teams have been reinventing this wheel for a while. A lead agent decomposes a task, hands pieces to specialist agents (each with their own model, prompt, tools), specialists work in parallel on a shared filesystem, events get persisted so the lead can check back in. Netflix’s platform team is using it to analyze build logs at scale.
The thing worth highlighting isn’t the function (everyone is doing this), it’s that the trace is provided by Anthropic, not written by you. This means the standard interface for evaluating, debugging, and auditing multi-agent systems is being claimed. OpenAI’s Agents SDK, CrewAI, LangGraph — every framework is fighting for this layer. Whoever wins it sets the default for “how to observe an AI agent” for the next two years.

2 · Karpathy Wrote a Guide for Coding Agents. It Made Claude Code Worse.
A footnote, since we’ll keep introductions brief. Andrej Karpathy — OpenAI co-founder, former head of Tesla Autopilot, the man who coined “vibe coding.” When he speaks publicly, the AI world stops moving for three days.
On April 29 he made a statement that made people sit up:
“I have never felt more behind as a programmer.”
Not because programming has gotten harder, but because as of some moment in December 2025, he can’t remember the last time he had to correct an AI. The agent’s code “just works now.”
He laid out his now-famous Software 1.0 / 2.0 / 3.0 framework:
- 1.0: humans write explicit code (the
if x > 0you remember) - 2.0: humans define datasets and objectives; neural networks learn weights from training (his own 2017 essay coined this)
- 3.0: humans program an LLM interpreter through prompts, context, tools, memory, and examples. His phrase: “the context window is the new RAM, the LLM is the new CPU, your program is the text you put in the context.”
His cleanest example was the OpenClaw installation. Old way: a 200-line bash script enumerating every dependency, platform, and error path — fragile and growing more fragile every month. New way: a copy-pasteable block of text you hand to your agent. The text describes the goal and the available tools; the agent inspects your environment, debugs along the way, and gets it installed.
This caught fire on Twitter. “Skill file” became this week’s new buzzword. People started rewriting their CLAUDE.md and AGENTS.md files using the four principles Karpathy summarized: think before coding, minimalism, surgical changes, goal-driven loops.
Then the plot turned.
A small AI coding company called Augment Code actually tested it. Forty real PRs from OpenClaw (medium complexity, 100–300 lines, excluding tests). Three runners: one called Auggie running on Opus 4.7, one Claude Code on Opus 4.7, one Codex on GPT-5.4. Compared a baseline AGENTS.md against AGENTS-karpathy.md (the same file plus the four principles). Six runs per PR. Independent LLM judge scoring on five axes.
The result is the most amusing — and most worth pausing on — data point of the week:
- Auggie and Codex both gained — small but statistically meaningful improvements. Consistent with “Karpathy is right.”
- Claude Code went the other way. Score dropped 0.07. Correctness down 0.07. Completeness down 0.06. Specifically: “trajectories are more conservative; on average about 5% fewer files touched per task.”
In English: Karpathy’s own guide, when added to Claude Code, made Claude over-cautious — touching too little, missing some implicit issues that needed fixing.
Augment’s summary, from their post: “Karpathy-style guidelines don’t transfer uniformly across agent harnesses and repositories. The objectives are meaningful for software engineering tasks, but each system’s baseline behavior is different.”

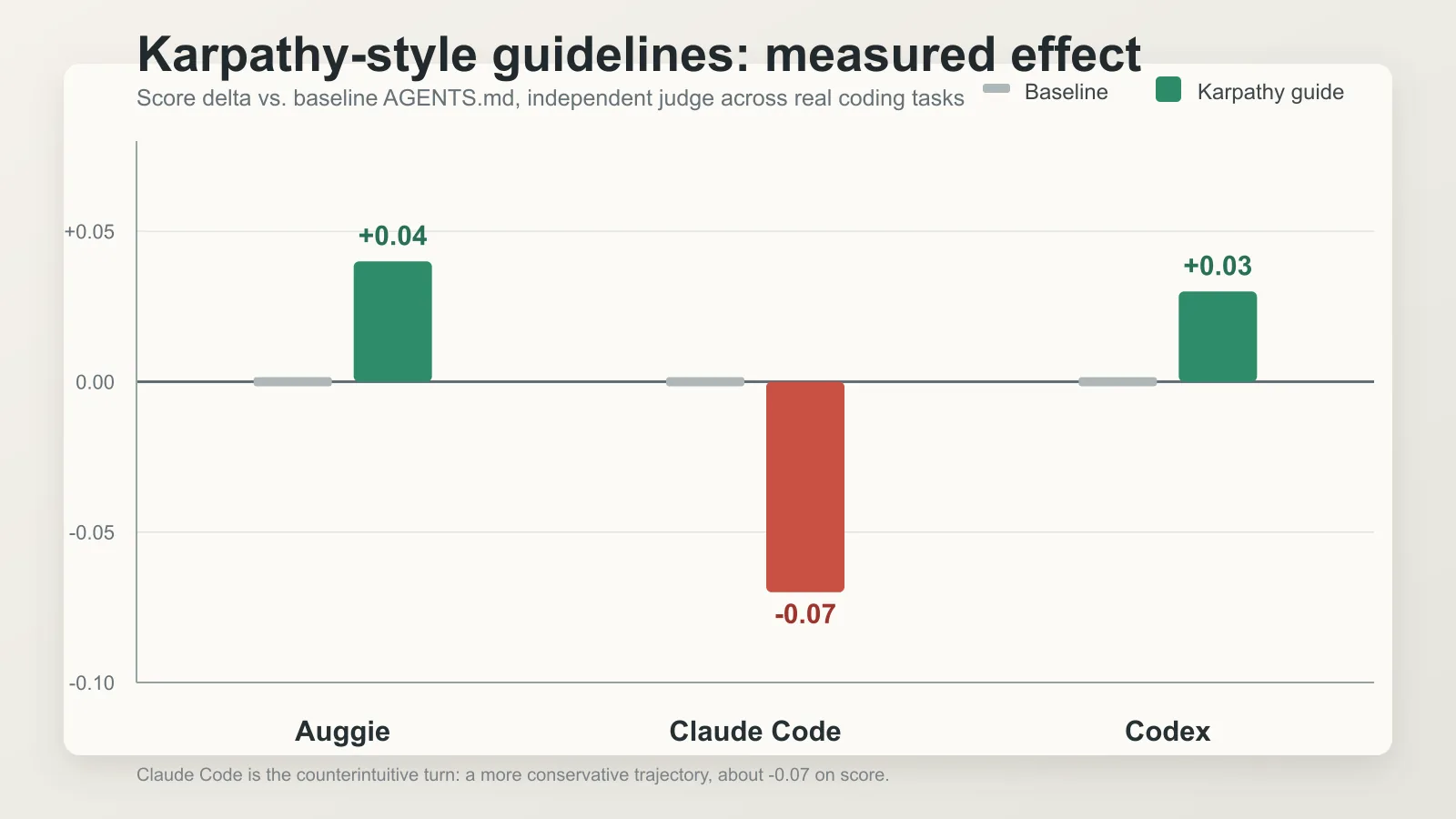
This pulls the entire issue’s thesis up onto its feet:
The model improves faster than the speed at which our “how to direct the model” instructions go stale.
Karpathy’s four principles aren’t wrong. They were designed to combat a specific failure mode of a specific baseline — agents being too aggressive, over-abstracting, scattering changes too widely. The problem is that Claude Code’s default behavior already fixed that failure mode. So adding the guideline becomes “fixing a bug that no longer exists” — overcorrection — and the model becomes timid.
The implication is unsettling: every “tell the model how to think” instruction you wrote this year should be assumed to expire — possibly in as few as six months. Best practice isn’t writing more refined instructions. It’s periodically re-running your instructions across multiple model versions to see whether they’re still helping. Manus founder Peak put it bluntly in another interview: “If swapping in a stronger model doesn’t yield improvement, your harness is dragging you down.”
This is the principle that most distinguishes “AI application engineering” from traditional software work — finished doesn’t mean done; done doesn’t mean don’t review again.
3 · Quick Brief — The Academic Frontline
If “independent grader plus rubric” sounds familiar by now, that’s because Anthropic didn’t invent it on May 6 from nothing. Academia has been doing it through January, February, and March. Two flagship papers:
Lumir et al., Agentic Rubrics as Contextual Verifiers for SWE Agents (arXiv:2601.04171, January 7). The problem: how does a software engineering agent get training rewards? Traditionally you run the test suite — but this requires every codebase to have an executable environment, which doesn’t scale. Their alternative: let an “expert agent” first interact with the codebase to generate a scoring-criteria yaml file (criteria + weights + scoring rules). Then candidate patches don’t need to execute tests; they’re scored by another independent grader against the rubric. On SWE-Bench Verified: +3.5 percentage points over the strongest prior baseline.
Wan et al., DeepVerifier (arXiv:2601.15808, January 22). Same idea, applied to Deep Research Agents — the kind of AI assistant that needs to do multi-step retrieval and synthesis. Highlights: it explicitly leverages the asymmetry between verification and generation — intuitively, you already know that recognizing a bad answer is easier than producing a good one. On the hard subsets of GAIA and XBench-DeepResearch, accuracy gains of 8–11%.
Reading them together, the consensus emerging in early 2026:
The asymmetry between generation and verification is the main axis of current AI progress. We’re getting better at designing verification — making it learnable, scalable, composable. What the model produces is becoming a relatively secondary debate. This echoes another Karpathy claim: “verifiability is the key to automation.” Domains that can be auto-verified (math, code, formal proofs) are the ones being automated fastest, because they have built-in ground truth. Creative writing, product judgment, strategic planning move slower not because models can’t do them, but because we haven’t yet figured out how to verify them automatically.
If you or your team are building anything with “AI auto-judges AI” in it, meta-evaluation F1 — the grader’s own accuracy — is a far more honest metric than “pass rate.” Don’t ask “what’s my agent’s pass rate?” Ask “how accurate are my grader’s verdicts in the first place?” That’s the most direct gift from this academic line to the application layer in 2026.
4 · Crossover — A Two-Month-Old Kitten Just Toppled a 70-Year-Old Archaeology Story
Why a cat in a tech magazine? Because methodologically, it’s the same story as the previous three sections — a sturdy decades-old narrative gets shattered from outside by a more direct line of evidence. Different skin, same skeleton.
Old story first, because it’s almost too elegant to question. Most cat-domestication science books still tell it this way:
About 9,600 years ago, in the Fertile Crescent (today’s Middle East and Mesopotamia), humans transitioned from hunter-gatherers to farmers. Where there’s stored grain, there are mice. Where there are mice, wildcats follow. Wildcats and early farmers formed a natural mutualism — humans domesticated the first house cats. Then, with Neolithic agricultural migration, house cats were carried from Anatolia to Europe roughly 6,000 years ago. Egyptian worship of the cat goddess Bastet (from 2890 BCE) is the cultural extension of this lineage.
So elegant: agriculture, archaeology, mythology, behavioral ecology, trade routes — every thread checks out. The flagship paper is Driscoll et al. 2007, based on mtDNA (mitochondrial DNA).
Where the trap was: mtDNA only traces the maternal line. It tells you about your mother’s mother’s mother, but not your full family tree. It’s like reading a company’s CEO list with no employee directory — you get a story that looks coherent but is missing serious information.
The new paper, published November 27, 2025 in Science by De Martino, Ottoni and colleagues, used different tools: whole-genome sequencing. 87 ancient, museum, and modern cat samples, full nuclear genome comparison. Three findings broke the old narrative:
- Modern domestic cats are genetically closer to North African wildcats (Felis lybica) than to Levantine wildcats — the domestication center shifts southwest, toward present-day Tunisia.
- The earliest specimen in Europe genetically identifiable as ancestral to domestic cats comes from Sardinia, Italy, carbon-dated to the 2nd century CE. House cats have been in Europe for only about 2,000 years, far later than the 6,000 previously assumed.
- Before the 2nd century CE, almost every “cat” skeleton excavated in Europe and Anatolia is European wildcat (a separate species), not domestic cat. A lot of archaeology reports describing “domestic cat burials” need to be reread.
The team added a sharper conclusion: the introduction of domestic cats correlated with the decline of native European wildcat populations — the former helped push the latter offstage. This isn’t a sweet “humans and cats” story; it’s a complete species-replacement event.
How did the modern domestic cat actually reach Europe? The most likely answer: on Roman trade and military ships, across the Mediterranean from North Africa, dispersing along the Sardinia → Italian peninsula → Gaul → Britain route. This route doesn’t appear in any creation myth — it’s written in the nuclear genome of every house cat alive today.

Not just because it’s interesting (although it really is). Because it’s the same methodological move as the previous three sections: replacing a long-trusted indirect signal with a direct observation properly bound to the object.
- AI agent auditing: communication logs (indirect) → action regret against counterfactual baseline (direct)
- AI agent grading: agent self-explanation (indirect) → independent grader on outputs (direct)
- Ancient cat dispersal: mtDNA (indirect, maternal-only) → whole-genome (direct, full pedigree)
If you take one piece of methodology away from this issue:
The stories most worth being suspicious of aren’t the obviously wrong ones — they’re the ones where everything seems to fit, every narrative checks out, every data point lines up. Those are the stories most likely to be built on some indirect signal, waiting for a more direct tool to come along.
And — if you happen to live with a small furry creature who pushes the water bowl across the floor at three in the morning — next time he’s grooming on your desk, you can let him know: his ancestors came over from North Africa about 2,000 years ago, on Roman ships, replacing the native European wildcats along the way. He’s not from Genesis. He’s from the nuclear genome. He’ll pretend not to hear.
5 · Quick Item — 220,000 GPUs Change Hands
Short fact, long structural signal.
The fact: Anthropic is taking the entire capacity of SpaceX’s Colossus 1 — a Memphis, Tennessee data center with over 220,000 NVIDIA GPUs. The two companies also expressed interest in collaborating on “multiple gigawatts of orbital AI compute capacity.” Yes, GPUs in space.
Why this is more interesting than it looks:
Musk has publicly called Anthropic “misanthropic” (the pun is intentional), and once wrote that “winning was never in the set of possible outcomes for Anthropic.” Anthropic itself is in a drawn-out legal fight with the Trump-era DoD. With cultural and political misalignment that strong, they signed the deal anyway. Musk’s stated reason: “no one at Anthropic set off my evil detector.”
Anthropic’s motivation is bluntly simpler: compute scarcity is overriding everything else. Their April 20 expansion with Amazon for “up to 5 GW of new capacity” doesn’t come online until late 2026 / early 2027. In the meantime, Pro and Max users have been hitting usage limits daily; paid-tier churn risk is the first dashboard on Dario’s Monday morning.

The uncomfortable truth this is telling you: the scarcest resource in AI right now isn’t algorithms; it’s GPUs that can physically be turned on. Karpathy at Sequoia preaching “build for agents, not for humans” — that’s the application layer. The Anthropic-SpaceX deal is the infrastructure layer voting with the same checkbook on the same proposition.
For anyone choosing vendors, deciding which compute path to lock their stack to, this is a price signal. Over the next 6 to 12 months, per-token AI inference cost may fall further than your current budgets assume — because capacity is coming online aggressively. That will reshuffle which “obviously useful but priced out of reach” AI applications enter the commercial frame. If you’ve been keeping a notebook full of agent ideas killed by cost, it might be time to take it out and run the math again.
Editor’s Postscript
Putting these five pieces together, this week’s bone is one sentence:
An externally-verifiable goal + the thinnest possible scaffold (one that doesn’t tell the model how to think) + a memory that accumulates across sessions — that is the May 2026 consensus shape of an AI agent stack.
The opposite of which is: every “how to think, what to avoid, what step comes next” instruction written into your CLAUDE.md or AGENTS.md will erode with every model release. While “how it gets verified, how it gets scored, how it gets sent back” instructions become more valuable with every model release.
Externalized scaffolding compounds in value. Internalized scaffolding compounds in drag. That’s the single bone running through five unrelated stories from this week.
Two threads I’ll be following next issue. First, the developer community’s hands-on takes on Outcomes — particularly r/ClaudeAI and the inevitable “things I broke” threads on X. Any sufficiently good product launch will have its first batch of edge-case bugs surfaced within seven days. That’s where the real learning happens. Second, Q2 technical responses to Sutton-Silver’s Era of Experience — particularly the sparse memory layers thread that a16z’s Why We Need Continual Learning references. They’ll determine how far Dreaming-style “semi-parametric memory” can actually go before fine-tuning becomes inevitable.
If you only read one thing this week, read Augment Code’s Karpathy-skills experimental report. Not because it’s the most important, but because it gave the case study of “no investigation, no right to speak” a clean, almost-textbook form: take a famous figure’s published guidelines, run a controlled comparison, use a consistent judge, and then honestly publish a counterintuitive negative result.
In a year when everyone in AI is shouting “ours is fastest,” writing on May 3rd that “our controlled experiment shows Claude Code with Karpathy’s guidelines actually scored 0.07 lower” is a kind of honesty in dangerously short supply.
Outside, a two-month-old creature is currently treating a coffee bean as a soccer ball across an entire living room. He doesn’t know he just turned the page on the Fertile Crescent story, doesn’t know there are 220,000 GPUs changing hands somewhere, doesn’t know a roomful of researchers are quietly redefining what “verification” means. Just as well. Let him play.
— Ed.
Comments