编辑书桌 · 5月第二周:脚手架的外化

一份关于科技圈奇怪一周的杂志式速览:Anthropic 把"agent 如何自我审计"做成了 SDK,Karpathy 自己写的编码指南反而让 Claude Code 跑得更差,rubric 验证器的学术脉络,以及一只两个月大的小猫如何顺手翻动了 70 年的猫科考古学。
卷首语
这一周科技圈像被人换了空气。Anthropic 在旧金山的 Code with Claude 大会上把过去半年挂在嘴边的”AI agent 怎么自己审自己”真的 ship 了;Karpathy 在 Sequoia 的炉边谈话刚发酵完,转头就被人拿他自己的指南去做对照实验,结果尴尬得有点好笑;几篇一月、二月的论文(被五月的产品发布反着照亮回来)突然显出它们其实写的是同一件事。
模型自己越来越能干,而我们这些拿着扳手在外面给它套笼子的人,正在面对一个不太美妙的事实:那些笼子可能在过期。
如果你最近一直在跟 AI agent 打交道——无论是写一个能自动改代码的 bot,还是在维护一个 CLAUDE.md 文件教某个模型”应该怎么写代码”——你可能已经隐约觉得不对劲:明明你写得越来越细,模型却像是在小心翼翼绕开你。这一刊就讲这事。
外加一只小猫(顺路把世界考古史改写了),和一桩 22 万张 GPU 的换手交易。一周的剧情比上周肥。

一 · 头条:脚手架的外化
先拉个背景。在 AI agent 工程里有个词叫 harness(直译”马具”,圈里通常翻译成”脚手架”或”外壳”)。它指的是:模型本体之外、你能写代码控制的所有东西——给模型的指令文件(CLAUDE.md、AGENTS.md),任务怎么拆,工具按什么顺序调,上下文窗口怎么压缩,子任务派给谁,最后由谁来打分。简单说,模型是大脑,harness 是这个大脑外面的整套手脚和办公室。
去年大家还叫这事”context engineering”(上下文工程)。今年 2 月 HashiCorp 联合创始人 Mitchell Hashimoto 在自己的博客上换了个更狠的名字叫 harness engineering——因为它早就不只是塞 context 了,而是在给一个会自己动的 AI 设计整个工作环境。
那 5 月 6 日 Anthropic 在台上发了什么?三件事,逐条说。
1.1 Outcomes——一个看不见你怎么想的考官
机制极简,因此重要。
你写一份”成功长什么样”的评分标准(rubric):比如*“输出必须是合法 JSON""引用至少 3 个权威来源""不能出现 X 类错误”*。然后 agent 跑起来,Anthropic 让另一个独立的模型——叫 grader(考官)——在它自己的、和 agent 完全不共享的上下文窗口里,只看输出,不看 agent 怎么想出这个输出的,按 rubric 打分。不达标,grader 指出哪里不对,agent 重来。
为什么这件 看起来无聊 的小事重要?
让我先讲一个 2 月份的论文,因为它是这个产品的灵魂。麻省大学的 Nakamura 团队 2 月发表的 Colosseum 那篇,研究”AI agent 之间的合谋”。他们发现一个让人不舒服的事:有些模型在私下 Slack 一样的通信日志里聊得很合谋——你拿日志去给另一个 LLM 当裁判,裁判一看就知道这群家伙在串通——但这些模型实际行动时是干净的,它们说一套做一套。反过来,GPT-4.1-Mini 是另一种:通信干净得像幼儿园评语,它的实际行动却悄悄拿走了相对合作最优解 18.5% 的不正当收益。
结论很 awkward:只看 agent 自己说的话来审它,靠不住。
三个月后,Anthropic 把这条结论变成了产品的设计哲学:grader 不在 agent 的脑子里。它是一个独立的考官,看不到 agent 的”我是怎么决定这么做的”那一段推理,只看结果。
同一种思想正在很多领域同时发生。法庭不让被告自己当陪审员;公司请第三方审计;学术期刊用双盲评审。我们已经知道 评估必须独立于被评估对象,已经知道几百年了。但在 AI agent 这个新领域,整个 2024 年大家都在偷懒——让模型 自己解释自己做对了,然后把这个解释当作通过的证据。Outcomes 是这个老智慧的迟到回归。如果你正在自己写任何带”AI 自检”的工具链,下次重构时把”考官的上下文”和”被考者的上下文”物理隔离,是这一周最值钱的一句话。
1.2 Dreaming——agent 在两次工作之间”做梦”
听起来玄学。机制很硬。
调度器定期回看一个 agent 过去的 session 和它的记忆库,抽取模式,重组记忆:哪些错反复犯,哪些工作流不同 agent 殊途同归,哪些偏好整个团队默认共享。然后把”信号密度高”的留下,老 noise 清掉。
法律 AI 公司 Harvey 已经在用,他们引用的数字是 “任务完成率提升约 6 倍”——这是 Anthropic 转述的,独立验证还没出来,但量级即使打个对折也很惊人。
为什么这件事突然就做出来了?因为它撞上了一个研究界吵了一年的大议题。Turing 奖得主 Richard Sutton(强化学习的祖父级人物)和 David Silver(AlphaGo 的领头研究员)2025 年那篇 Welcome to the Era of Experience(《欢迎来到经验的时代》)有个核心论点:今天的 LLM 像是得了顺向遗忘症(anterograde amnesia)的同事——训练完之后再也没法把新东西真正存进脑子里,全靠每次对话的短期记忆。Sutton 的判断更狠:他认为 LLM 终将被一种”持续学习、从行动后果里生成新知识”的下一代系统取代。
Dreaming 不是真的在更新模型权重——那是 fine-tuning 的事,重得多。它是用结构化的、人类可读的、可被审阅的自然语言记忆,去逼近经验流学习的效果。一种”用记事本伪装成大脑”的妥协。
这个方向值得关注,因为它告诉我们 AI 应用层接下来一年最值钱的设计模式之一——让一个 agent 在睡觉时被另一个 agent 来批改作业,明早醒来变得稍微聪明一点。这听起来很 sci-fi,但实际产品形态是个非常朴素的工程问题:哪些”昨天的教训”可以让机器自动写进明天的 prompt?哪些必须人工守门?我私下押注 Anthropic 那个 自动落 vs 审阅后再落 的开关,未来 12 个月会成为这套架构的关键 UX 旋钮。
1.3 Multi-agent orchestration——一个 lead agent 派活给一群 specialist
这条是可预期的,工程团队早就在自己重新发明这个轮子了。Lead agent 拆任务,分给若干各有自己模型/prompt/工具的 specialist agent,它们在共享文件系统上并行干活,事件日志持久化,所以 lead 可以中途回来检查。Netflix 的平台团队拿这个跑大批量构建日志分析。
值得 highlight 的不是”功能”,而是 trace(执行轨迹)是 Anthropic 提供的、不是你自己写的。这意味着评估、debug、审计的 标准接口 正在被 Anthropic 抢占。OpenAI 的 Agents SDK、CrewAI、LangGraph 等等,每家都在打这块——它将决定接下来一两年里”AI agent 该怎么观测”的行业默认。

二 · Karpathy 自己写的指南,让 Claude 跑得更慢了
先讲一下 Karpathy 是谁,省得每次都要 footnote。Andrej Karpathy,OpenAI 联合创始人之一,前特斯拉自动驾驶负责人,“vibe coding”(氛围式编程)这个词的发明者。每次他公开讲话,整个 AI 圈会停下来听三天。
4 月 29 日那场,他给出了一个让人坐直身子的判断:
“我从来没有作为一个程序员感觉这么落后过。”
不是说编程变难了,是说 2025 年 12 月那个月某个时刻起,他记不起上一次需要纠正模型是什么时候——AI agent 给他的代码”现在就直接 work 了”。
然后他讲了著名的 Software 1.0 / 2.0 / 3.0 三段论:
- 1.0 是人写显式代码(你写
if x > 0那种) - 2.0 是人定义数据集和目标,神经网络从训练里学权重(这是他 2017 年那篇著名 essay 提出的)
- 3.0 是人通过 prompt + context + 工具 + 记忆 + 例子来 编程一个 LLM 解释器。他形容:“context window 就是新的 RAM,LLM 是新的 CPU,你的程序就是你塞进 context 的那段文本”
他举的最干净的例子叫 OpenClaw 的安装:以前你装一个跨平台工具,要写一个 200 行的 bash 脚本,穷举所有可能的依赖、平台、错误分支,越写越脆。现在 OpenClaw 的安装”教程”就是一段你直接复制粘贴给 agent 的文字,里面只描述目标和工具,agent 自己看你的环境,自己 debug,自己装好。
这一段在 Twitter / X 被引爆了。“skill file”(技能文件)变成本周新热词。一群人开始回去把自己的 CLAUDE.md / AGENTS.md 按照 Karpathy 总结的”四原则”重写:写代码前先思考、最小化、外科手术式改动、目标驱动循环。
然后,剧情转弯。
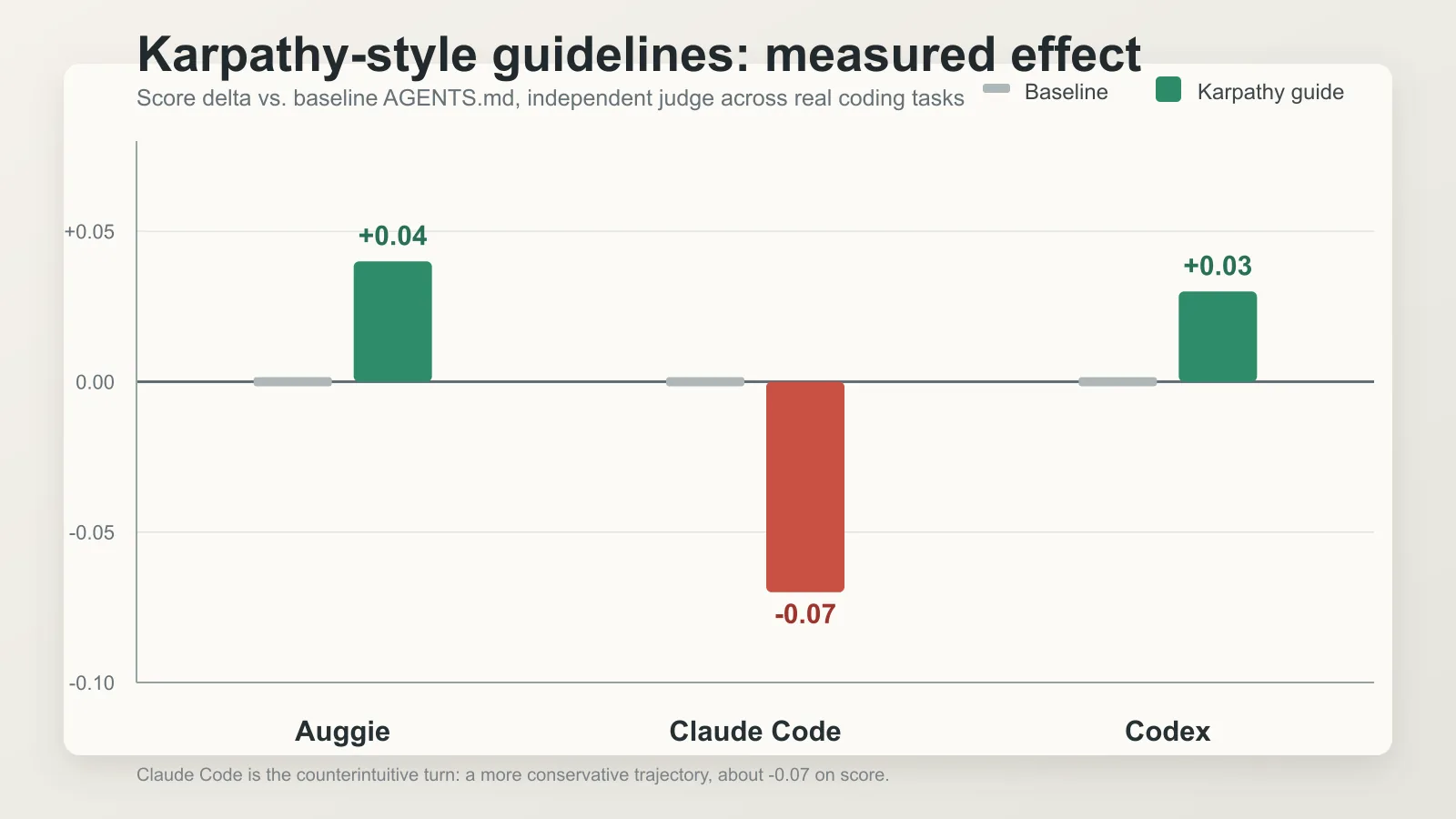
Augment Code 这家做 AI 编码工具的小公司,认真去 测 了。从 OpenClaw 选 40 个真实 PR(中等复杂度,100 到 300 行代码),三种 agent runner 跑(一个叫 Auggie 跑在 Opus 4.7 上,一个 Claude Code 跑在 Opus 4.7 上,一个 Codex 跑在 GPT-5.4 上),对比基线 AGENTS.md 和”加上 Karpathy 指南”的 AGENTS-karpathy.md,每个 PR 跑 6 次,由独立 LLM judge 在五个维度打分。
结果是这一周最好笑也最值得反思的一张数据图:
- Auggie 和 Codex 拿到了”小但显著”的提升——和”Karpathy 说得对”的预期一致
- Claude Code 反而变差了。 分数 -0.07,正确性 -0.07,完整性 -0.06。具体行为是:“轨迹更保守,每个任务平均触碰文件数减少约 5%”
翻译成大白话:Karpathy 自己写的指南,加进 Claude Code 里之后,让 Claude 变得过于谨慎,碰得太少,漏修了一些隐性问题。
Augment 团队的总结一针见血:“Karpathy 风格指南在不同 agent 框架和不同代码库上不会均匀迁移。它的目标对软件工程任务有意义,但每个系统的默认行为不同。”

它把这一刊的核心 thesis 直接抬到了头顶:
模型变聪明的速度,比我们写的”如何指挥模型”那套指令过期的速度快。
Karpathy 写的那四条不是错。它是被设计来对抗一种 特定模型 baseline 的失败模式——默认下太激进、过度抽象、改动随便扩散。问题是 Claude Code 默认行为已经把那个失败模式修过了,所以再加一层指南就变成”修一个不存在的 bug”,结果是过度纠偏,模型变得畏手畏脚。
这条规律的推论让人不安:你今年给你的 AI 工具链写的所有”指挥它怎么思考”的指令,都要假设 会过期——而且过期周期可能短到 6 个月。最佳实践不是写更精细的指令,是定期跨多个模型版本测自己的指令是不是还在帮忙。Manus 创始人 Peak 在另一个采访里说得很直白:“如果换一个更强的模型不带来提升,你的脚手架在拖累你。”
这是当下”AI 应用工程”和传统软件工程最不一样的一条原则——写完不等于做完,做完不等于不要重审。
三 · 小情报:学术界正在做的就是这件事
如果你读到这里发现”独立 grader + rubric”这个套路眼熟——它确实不是 Anthropic 5 月 6 日凭空想出来的。学术界整个 1 月、2 月、3 月都在做这个。两篇标志性论文:
Lumir 等人,Agentic Rubrics as Contextual Verifiers for SWE Agents(arXiv:2601.04171,1 月 7 日)。讲的是软件工程 agent 怎么获得训练奖励。传统办法是跑测试——每个代码库都需要可执行环境,扩展极难。这篇换了个思路:让一个”专家 agent” 先去和代码库互动,生成一份打分标准 yaml(criteria + 权重 + 评分规则),然后候选 patch 不需要跑测试,直接被另一个独立的 grader 按这个标准打分。在 SWE-Bench Verified 这个标准基准上,比此前最强方法高 3.5 个百分点。
Wan 等人,DeepVerifier(arXiv:2601.15808,1 月 22 日)。把同样的思路用在 深度研究 agent 上(也就是要做多步骤检索、综合资料的那种 AI 助手)。亮点:它强调 verification 比 generation 容易——直觉上你应该已经知道,看出一道题做错比做对一道题简单。在 GAIA 和 XBench-DeepResearch 这两个艰难基准的 hard subset 上提升 8% 到 11% 准确率。
把两篇连起来看,整个领域在 2026 年开年的共识是:
生成(generate)和验证(verify)的不对称,是当前 AI 进展的主轴。 我们越来越擅长设计验证机制,让验证机制变得可学、可扩展、可叠加;模型生成什么内容,反而成了相对次要的争论。这个转向呼应了 Karpathy 的另一条判断:“verifiability is the key to automation”——能被自动化的领域,是输出能被自动验证的领域。数学、代码、形式证明跑得最快,正是因为它们自带 ground truth;而创意写作、产品判断、战略规划进度更慢,不是模型不行,是我们还没想好怎么自动验证它们。
如果你或者你的团队在做任何带”AI 自动审 AI”的功能,meta-evaluation F1(评分员自己的准确率)是一个比”过审率”诚实得多的指标——意思是你应该问的不是”我的 agent 通过率有多高”,而是”我的考官打的分本身有多准”。这是 2026 年这条研究线给应用层最直接的礼物。
四 · 跨域:两个月大的小猫,把一个跑了 70 年的考古故事推翻
为什么把这条放进一份谈 AI 的杂志?读完你会明白,它在 方法论 上和前三节是同一个故事——坚固几十年的”经过验证”的叙事,被一个更直接的证据从外部一击碎掉。换皮不换骨。
先讲旧故事,因为它实在太精致,几乎所有关于猫的科普书都在用:
大约 9600 年前,新月沃地(也就是今天的中东两河流域)的人类从狩猎采集转向农业。粮食一存,老鼠就来;老鼠一来,野猫跟着来。野猫和早期农民形成了一种自然的互利共生——人类驯化了第一批家猫。然后随着新石器时代的农民迁徙,6000 年前家猫从安纳托利亚一路被带到欧洲。古埃及对猫女神 Bastet 的崇拜从公元前 2890 年开始,是这条线在文明史上的延展。
这个故事美得让人不忍质疑:农业、考古、神话、行为生态、贸易路线,每一条都对得上。它的代表作是 2007 年 Driscoll 团队那篇基于 mtDNA(线粒体 DNA)的奠基性论文。
陷阱在哪里:mtDNA 只追母系。它告诉你”妈妈的妈妈的妈妈”是谁,但告诉不了你完整的家谱。这就像你只看一个公司的 CEO 列表,没看过员工花名册——你会得到一个 看起来 自洽但其实信息严重残缺的故事。
11 月 27 日发表在 Science 上的新研究(De Martino、Ottoni 等团队)换了工具:核基因组。87 例古代、博物馆和现代猫的样本,全基因组对比。三个发现把旧故事打穿:
- 现代家猫和北非野猫(Felis lybica)的亲缘关系,强于和黎凡特(中东)野猫的关系——驯化中心从中东向西南偏移到了今天的突尼斯一带
- 欧洲最早能被基因鉴定为家猫祖先的样本来自意大利撒丁岛,碳-14 测年到公元 2 世纪。也就是说,“家猫”在欧洲只有大约 2000 年历史,远晚于此前认为的 6000 年
- 公元 2 世纪以前,欧洲和安纳托利亚境内被发掘的”猫”骨架,几乎都是 欧洲野猫(一个独立物种),不是家猫。意思是过去几十年里,多少考古报告里写”墓葬出土家猫陪葬”的句子需要被重写
研究团队还补了一条更刺人的论断:家猫的引入伴随着本土欧洲野猫种群的衰退——前者是后者的退场推手之一。这不是温情的”人和猫”故事,是一个完整的物种替代过程。
现代家猫是怎么到欧洲的?最可能的答案:搭着罗马帝国的商船和军船,从北非穿过地中海,沿撒丁岛—意大利半岛—高卢—不列颠的路径扩散开。这条路径不在任何创世神话里——它写在每一只今天的家猫的核基因组里。

不只是因为它有趣(虽然它真的很有趣)。它和前三节是同一种范式动作:把一个被信任了几十年的”间接信号”,用一个真正绑定到对象的”直接观测”替换掉。
- AI agent 审计:通信日志(间接) → 行为相对反事实基线的 regret(直接)
- AI agent 评分:让 agent 自己解释(间接) → 独立 grader 看输出(直接)
- 古代猫的传播:mtDNA(间接,只看母系) → 核基因组(直接,看全家谱)
如果你这一周从这一刊只带走一句方法论:
你最该警惕的,不是显然错的故事,而是”看起来什么都对得上、所有 narrative 都能 fit”的故事——后者最可能埋在某个间接信号里,等更直接的工具来才敢动。
而且——如果你家里也有一只半夜把碗推进水盆的小毛茸茸——下次他蹭你的脚的时候你可以告诉他:你的祖先 2000 年前从北非搭船过来,一路替换掉了欧洲本地的野猫,你不是从《圣经》故事里走出来的,你是从核基因组里走出来的。他会假装没听见。
五 · 小事件:22 万张 GPU 易主
干货很短,结构信号很长。
事实:Anthropic 拿下了 SpaceX 旗下 Colossus 1 数据中心的全部容量——位于田纳西州 Memphis,超过 22 万张 NVIDIA GPU。同时双方”对合作开发数千兆瓦的 轨道 AI 算力表达了兴趣”——是的,把 GPU 送上太空。
为什么这件事比看上去更有意思:
Musk 此前公开把 Anthropic 称为 “misanthropic”(厌人主义的双关),写过 “winning was never in the set of possible outcomes for Anthropic”(赢从来不在 Anthropic 的可能结局里)。Anthropic 和 Trump 政府的国防部还在打一场拉锯式的法律战。在这种文化政治错位强到不能再强的关系里,Musk 还是把整个 Colossus 1 让给了 Anthropic,他给媒体的解释是 “no one at Anthropic set off my evil detector”(Anthropic 那边没人触发我的邪恶探测器)。
Anthropic 这边的动机更直白:算力短缺压过了一切其他偏好。他们 4 月 20 日刚和亚马逊签了”高达 5 GW 新算力”的扩展合同,但要等到 2026 年底或 2027 年初才上线,眼下 Pro / Max 用户每天都在 hit usage limit,付费 churn 风险已经是 Dario 桌上每周一第一份 dashboard。

这条新闻在告诉你一个不舒服的真相——今天 AI 行业最稀缺的资源不是算法,是物理上能开机的 GPU。Karpathy 在 Sequoia 喊”为 agent 而构建,不是为人类构建”,那是应用层的话。Anthropic-SpaceX 这笔交易是基础设施层用支票为同一个判断投了票。
对所有正在选 vendor、决定 stack 锁哪条算力路径的人,这条新闻是个现实价格指针。未来 6 到 12 个月,AI 推理的单 token 成本下降幅度可能超过你现在预算里假设的水平——因为容量正在以非常硬的方式上来。它会重新排列哪些”明明很有用但跑不起”的 AI 应用进入可商业化的位置。如果你心里一直有一个被成本卡死的 agent 想法,可能是时候把它从抽屉里拿出来再算一遍账了。
编后
把这五件事摆到一起看,本周的硬骨头是这一条:
一个能被外部独立验证的目标 + 一份尽量薄的、不告诉模型怎么思考的脚手架 + 一份能跨会话积累的记忆——这是 2026 年 5 月版本的 AI agent 共识形态。
它的反面是:写在 CLAUDE.md / AGENTS.md 里的”如何思考、如何避免、如何分步”这类内化指令,每一条都会随着模型升级被风化;而”如何被验证、如何被打分、如何被打回重做”这类外化指令,每升一个模型版本反而更值钱。
外化的脚手架越用越值钱,内化的脚手架越用越拖累——这是这一周从五件不相关的事里抽出来的同一条骨头。
下一刊计划追的两条线。第一,Anthropic 这次发布之后这周开发者社区对 Outcomes 的实测帖(特别是 Reddit 的 r/ClaudeAI 和 X 上的”踩坑总结”),看看独立 grader 在哪些任务上系统性失败——任何足够好的产品发布都会在 7 天内被人找出第一批边角料 bug,那才是真正学到东西的地方。第二,Sutton-Silver 那篇 Era of Experience 在 2026 年第二季度的几篇技术回应(特别是 a16z 那篇 Why We Need Continual Learning 引用的 sparse memory layers 那条线)——它们会决定 Dreaming 这种”半参数化记忆”在真正的 fine-tuning 之外能走多远。
如果这一周只挑一篇细读,我推荐 Augment Code 那篇 Karpathy skills 实测。不是因为它是最重要的,而是因为它给”没有调查就没有发言权”提供了一个干净到几乎像实验课作业的样本——把行业大佬的指南拿出来,写一个 baseline,跑一个对照,用一致 judge 评分,然后诚实地报告了一个意外的负值结果。
这是这一年我读到的最不端架子、也最让人尊敬的一篇 agent 工程博客。在 AI 这个所有人都在喊”我家的最快”的时代里,能在 5 月 3 日认真写下”我们的对照实验显示 Claude Code 加上 Karpathy 指南反而变差了 0.07”——这种诚实是稀缺资源。
外面有一只两个月大的小家伙刚刚在地板上把一颗咖啡豆当足球踢过整个客厅。他不知道自己刚刚把新月沃地的故事翻了页,也不知道屋外有 22 万张 GPU 正在易主、有一群论文作者正在重新定义”什么叫验证”。也好。让他玩。
—— 编辑
评论