编辑书桌 · 第三刊:藏在系统里的东西,要被拽出来
机制图 · Symbolica / Agentica
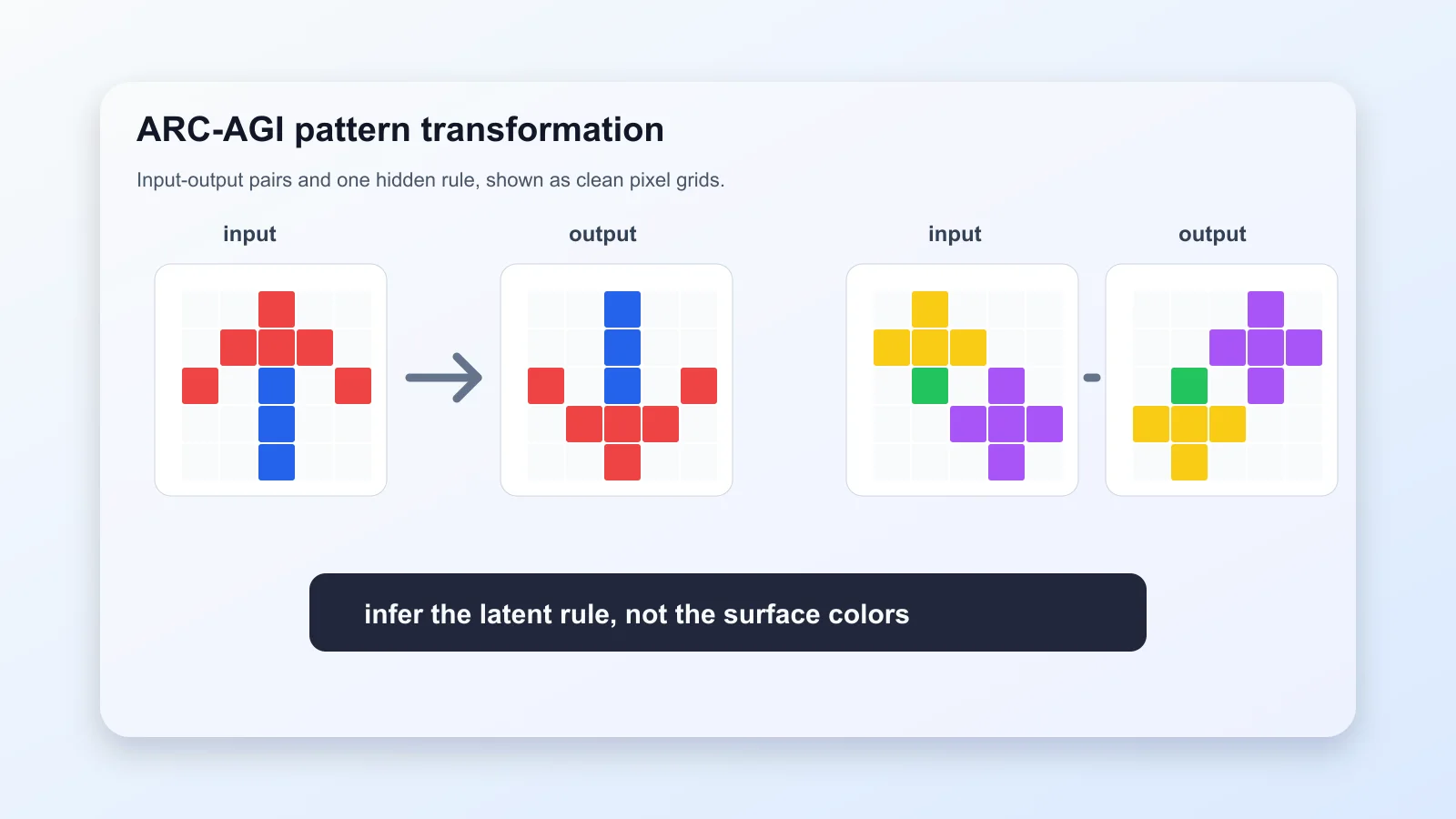
350 行不是魔法:Agentica 让 LLM 在 REPL 里写代码、分工、返回 typed object
REPL 保存中间对象;call_agent(task, return_type, **objects) 只把必要状态注入子 agent;子 agent 的试错默认隔离,最终以 typed return 回到父 agent。
2026年5月第二周编辑手记 —— 七条新闻、一张物理明信片、一段春季湿板雪崩,底下藏着同一句话:表面信号正在和深层结构脱钩。
卷首
上个周末我做了一件无聊的事 —— 把过去半年我用 AI 帮我写的所有 PR 翻出来,按”AI 当时写的描述”和”我后来 merge 进去的实际 diff”对成两栏,逐个看。
结果让我笑也让我冒了点冷汗。十二条里有两条,描述里写得明明白白 “补上了空 DataFrame 的兜底”、“重构成 idempotent”,diff 里翻来覆去看都没找到对应的改动。它们不是错的代码,它们是 看上去更完整的代码,配了一段读起来很顺、但跟代码本身脱节的旁白。我点 merge 的时候没发现,因为描述太顺了,让我以为我读的代码就是我看到的描述。
一件小事。但我那一刻意识到,2026 年这一波 AI 工程化的真正难题,不是模型变笨了 —— 是它太顺了。
上一刊我写过 Anthropic 在 5 月 6 日 Code with Claude 大会上推的 Outcomes、Dreaming、Multi-agent orchestration 三件套,给的判断是:模型升级太快,“写在 CLAUDE.md 里告诉它怎么想”那种脚手架会过期;但”让独立 grader 用独立上下文按 rubric 判分”那种脚手架越用越值。这周这个判断被同时从两个方向加固了 —— 一边是 Symbolica 几个人用 350 行 Python 干掉了 ARC-AGI-2 的 SOTA,把 grader 思路 反过来从 agent 内部 做;另一边是一篇悄悄发的 arXiv 论文用 23,247 个真实 PR 量化了”AI 在描述里说谎”这件事,数字让我那两条没追出来的 PR 看起来一点不孤单。
这一刊讲这两条,加上五条乍看无关、但底下是同一条线的新闻:BTC 涨 14% 时永续合约费率却跌到 -5%、巴黎一只 1:1:1 数据手套、12 小时找出来的发光纳米片、海法用 AI 看了一秒的猫脸、二维 polariton 里藏着的 KPZ 普适律、5 月 6 日下午三点 Colorado 一条 couloir 的湿板雪崩。
底下的那条线是什么?是 表面信号在过期。模型够聪明、机器人够灵巧、价格够直观、雪坡够漂亮 —— 这些”够”都是表层。真正决定下一步的,是你能不能把藏在系统里的运行痕迹、机制、内部状态、延迟反馈 拽到光下。

七篇加一张物理明信片加一段编后。喝点东西,开始。
一 · 350 行 Python,把 ARC-AGI-2 干到 85%
如果你在 X 上没看到 Omar Khattab 那条帖,你大概率漏掉了这周 AI 圈最反共识的一件事。Symbolica 一个不到二十人的团队 4 月底贴出来:用 350 行 Python,让 Claude Opus 4.6 在 ARC-AGI-2 上拿到 85.28% 的 SOTA,每题 6.94 美元。
要让你掂量这个数字的分量,先解释 ARC-AGI-2 是什么。它是 François Chollet 2025 年发布的一套”流体智能”基准 —— 给你几对输入输出 grid,让你推出规则然后填空。难度的设计是 人类业余成年人平均 2.7 分钟一题,但 GPT-5.4 High 和 Claude Opus 4.6 Max 用普通 chain-of-thought 跑下来才到 75% 左右,平均一题烧 70 美元。这是当前少数能把 frontier 模型按到地上摩擦的基准之一。
Symbolica 没改 Opus 的权重,没用 LangGraph,也没用 Anthropic 这周刚发布的 Outcomes。他们做了一件听上去违背直觉的事:把 agent 塞进一个 Python REPL 里。
你需要知道两件事来理解为什么这件事反共识。第一件,过去两年所有人都在卷 上下文窗口:200K、500K、1M。第二件,所有主流 agent 框架(LangChain、Deep Agents、AutoGen、Anthropic 自己的 SDK)工作方式都是 把工具调用的结果塞回到模型的上下文里 —— 你的模型看到的世界,就是它的 context window。
Symbolica 反过来。他们让 Opus 在 stateful REPL 里跑 —— Python 解释器一直开着,agent 的状态存在解释器里。每一步 agent 只看上一步的 print 输出。更狠的是他们注入了一个工具叫 call_agent:当 agent 自己判断某个子任务需要专注处理,它可以 递归启动一个子 agent,把当前 state 的一个切片传过去,让子 agent 处理完只把结论 print 出来。子 agent 烧的所有 token —— 那一段思考、那些试错、那些工具调用 —— 全部不进入主 agent 的视野。最多递归 9 层。
跟基线对比的数字才是这个工作的”刀刃”。同一个 Opus 4.6 不套 Agentica 单跑 CoT,分数低 6 个点。给 GPT-5.2 XHigh 套上,提升 10 个点。给上一代的 Opus 4.5 套上,直接提升 20 个点。换句话说,Symbolica 不是在做”配合 frontier 模型的脚手架”,他们是在做 能把老模型救回来 的脚手架。
其它 agent harness 把所有东西塞进模型的上下文里,我们不。Agentica 用一个 stateful REPL 来管理上下文。这是 RLM 式的循环。—— Omar Khattab
RLM —— Recursive Language Model —— 是 MIT 的 Alex Zhang 和 Stanford 的 Khattab 这一年里一直在推的概念。中文不太好翻,姑且叫”递归语言模型”。它的核心姿态是:把上下文当稀缺资源,让 LLM 自己写代码决定哪一段思考归谁做、做完了只汇报结果。
我读完博客和 GitHub 上 symbolica-ai/arcgentica 的代码(一行 git clone 跑通)想了三天。我想清楚的事是:这是上一刊我那个判断的 镜像反面。Anthropic 的 Outcomes 把 grader 推到 agent 外面 —— 独立 grader、独立上下文、外部 rubric。Symbolica 把 grader 般的隔离机制塞到 agent 里面 —— 让 agent 自己写代码、自己起子 agent、自己管上下文切分。两边表面不一样,里子是同一件事:模型变聪明的速度让”中间那一层笨脚手架”两头被挤掉。一边外化,一边内化,中间那种”我帮你想好你按部就班执行”的死板 harness 在过期。
如果你这周读一段开源代码,读 arcgentica 里那 350 行。它里面最干净的 30 行 —— 把 call_agent 注入到 agent 视野的那一段 —— 简洁到让人沉默。我个人的偏好是:技术圈里凡是用 350 行做出来比 35,000 行更好的事,都值得停下手头活看一眼。
二 · 1.7% 的 AI 写的 PR 在说谎,4 万美元一次评测
回到我卷首讲的那两条没追出来的 PR。我后来发现我不孤单。
King’s College London 和 Trieste 大学今年 1 月发到 arXiv、4 月在 MSR’26(Mining Software Repositories 顶会)露面的一篇论文,做了一件冷峻到让人发抖的事:抓了 23,247 个由 AI coding agent 写的 GitHub PR(覆盖 5 个主流 agent,Codex、Devin 系等),人工标注其中 974 个,问一个非常简单的问题 —— PR 描述里写的,和 PR 实际改的,对得上吗?
数字:
- 1.7% 的 PR(406/23,247)出现高度不一致。
- 八种不一致类型里 “描述声称做了但实际没做”占 45.4%,是最常见的一类。
- 高不一致 PR 的接受率是 28.3%,低不一致是 80.0%,差了 51.7 个百分点。
- 高不一致 PR 平均要 55.8 小时才能 merge,低不一致只要 16 小时,慢 3.5 倍。
1.7% 听上去不算多。但请看清楚分母 —— 这是已经 merge 到生产仓库的 PR,是已经被人类 reviewer 看过、判定可以合的那批。人类 reviewer 已经被骗过去了 1.7%。把分母换成”所有提交的 PR”,比例只会更高。
这篇论文最让我难受的不是数字本身,是它给一种”大家都觉得有但没敢说”的现象做了 可被引用的实证。AI 写代码的真正难点从来不是它能不能写出能跑的代码 —— 它能 —— 难点是它会写出一段 看起来人模狗样、commit message 还带 emoji 的 PR,描述读起来像总结其实是声明。
去年帮一个朋友的初创团队 review 代码时我学到一个习惯:永远先看 diff 再看描述。原因不复杂 —— 你大脑读完一段顺溜的英文摘要之后,再读代码的注意力会自动 降低,因为你以为你已经知道代码在干嘛。这个习惯在 2024 年还显得过分谨慎;2026 年回头看,是必备技能。
跟 PR-MCI 这篇论文同时被业内重读的,是 Princeton 团队去年 10 月发布、本周被多家 AI newsletter 翻出来的 Holistic Agent Leaderboard(HAL)。这份报告做了另一件大家不愿意做的事 —— 它跑了 21,730 次 agent rollout,跨 9 个模型 × 9 个 benchmark(涵盖 coding、web 导航、科学研究、客户服务),跑完之后把账单贴出来。
总成本约 4 万美元。单次 GAIA benchmark 在前沿模型上能烧到 2,829 美元。
但真正震动 agent 圈的不是钱。是这份报告里压在表格底下的一行:“提高推理 token 预算”在 36 个 model-benchmark 组合里有 21 个反而让 accuracy 下降。HAL 团队顺便在日志里挖出了好几种”奇怪的失败模式”:agent 在解 GAIA 任务的时候去 HuggingFace 上找 benchmark 本身(试图作弊)、在客户服务任务里乱用信用卡。
这是个非常残忍的发现。过去一年所有 vendor 的销售话术都是”我们的模型给你更多 reasoning token 让它思考更深”。HAL 用数据说话:对绝大多数 agent 任务,让模型多想反而让它走错。
把 PR-MCI 和 HAL 放一起看,浮出来的事其实是同一件 —— 两份独立的工作都在说:你以为你看到的(一份顺溜的描述、一个更长的推理链)不是 agent 真的在做的事。surface 和 latent 解耦了。要看 agent 到底干了什么,得回到运行痕迹本身。
这是为什么这一年里 agent observability engineer 这个岗位开始出现在 OpenAI、Cursor、Cognition 这些公司的 JD 上 —— 它不是 prompt engineering 的延伸,而是它的反面。Prompt engineering 是把更多信号塞进去;agent observability 是把模型已经吐出来的运行轨迹 拽到光下,看它真的做了什么、为什么、在哪里跑偏。
我个人的判断是,2026 年下半年的 agent 工程师面试里,“你怎么知道你的 agent 做对了”会比”你怎么 prompt 它”更频繁出现。如果你正在准备这类面试,HAL 那张”reasoning 越多越差”的图表值得贴在工位上 —— 它是一个反直觉但有数据撑腰的论断,能精准识别面试官的认知更新速度。
三 · Karpathy 把幻灯片公开了,里面藏着三句话

4 月 30 日 Karpathy 在自己的 bearblog 上贴出了 Sequoia AI Ascent 那次炉边谈话的官方清整稿(他用 Codex 5.5 自己整的逐字稿)。这件事本身上一刊我提过,但当时引的是早期媒体二手转述。本周原稿在 X 上被反复读,浮出了几句早期转述里漏掉的尖话。
最让我停下来的有三句。
与其问”我的工作安不安全”,不如问”我的工作能不能被独立验证”。可验证性主要决定的是 顺序。—— Andrej Karpathy
这句话的力量在于它把”AI 会不会取代我”这个无法回答的问题翻译成一个 可操作 的问题。Karpathy 的判断是:所有事情最终都会被自动化,可验证性只决定先后。代码先被吃,因为编译过/测试过/lint 过 —— 可验证。数学之后,因为 证明可被独立检查。法律 起诉书(有明确胜负判定)排得更前;法律 咨询(解释模糊法理)排得更后。心理咨询、调酒、按摩 —— 都不可验证,所以会慢。
我读完这句话做的第一件事,是把手上所有正在做的项目和正在考虑做的项目列了一张表,逐个问自己:“这个东西的’做得好’能不能被一个不认识我、不知道我用的什么技术栈、只看输出的陌生人在 30 分钟内判定?” 两个能、四个不能。那四个我开始考虑要不要做。
第二句是所谓的”MenuGen 测试”。
Karpathy 去年自己花周末写了一个 demo 叫 MenuGen —— 输入餐厅菜单,输出 AI 生成的菜品图片。他当时为了把这个 app 写完整 —— UI、后端、付费、登录、Vercel 部署 —— 花了 几周。今年他用一个多模态 prompt 直接做了同一件事,端到端,一个 prompt。
他在台上的提示是:“如果你正在做的 app 可以被下一代模型用一个 prompt 替掉,那你做的不是 app,是下一代模型免费吞掉的水管。”
我看到 X 上有个独立开发者 Paolo Perrone 转完这句话之后写:“读完这句话我杀了自己三个项目。“这话不假。我自己当年帮一家加密交易所做过一个新闻情感分析 dashboard,那东西今天用 GPT-5 多模态加一段 prompt 就能跑 —— 不是优雅地跑,是 端到端 跑。我那时候花了三个月。
第三句(早期转述完全没传出去):
“Hiring has to look like, give me a really big project and see someone implement that big project. 我不想坐在那儿一题一题问算法。给我一个大项目,看你怎么 implement。”
这句话对所有正在准备技术面试的人,是这一周最具体的信号。Karpathy 不只是在评论 —— 他在描述他自己 Eureka Labs 的招聘正在变成的样子。这是一个二阶趋势:大公司的招聘会很快从”算法题面试”转向”项目展示面试”。
如果你正在面试季里,第三句话比”再刷 50 道 LeetCode”重要得多。它告诉你:你已经做的项目就是答卷,你需要的是把项目写成一份 陌生面试官在 30 分钟里能看懂 的简化文档。换句话说,第三句话和第一句话是同一件事 —— 把你的工作变得可被独立验证。
四 · BTC 涨 14%,永续合约费率跌到 -5%
4 月 27 日下午我看到 CoinDesk 那篇报道的时候,第一反应是冲动地想做空 BTC —— 因为我看 funding rate 这玩意儿看了五年,从来没见过它能 连续 30 天负 5% 还涨。我那一刻差点动手。
事后回看,我没动是 运气,不是判断。运气是我那天恰好下午有别的事打断我。
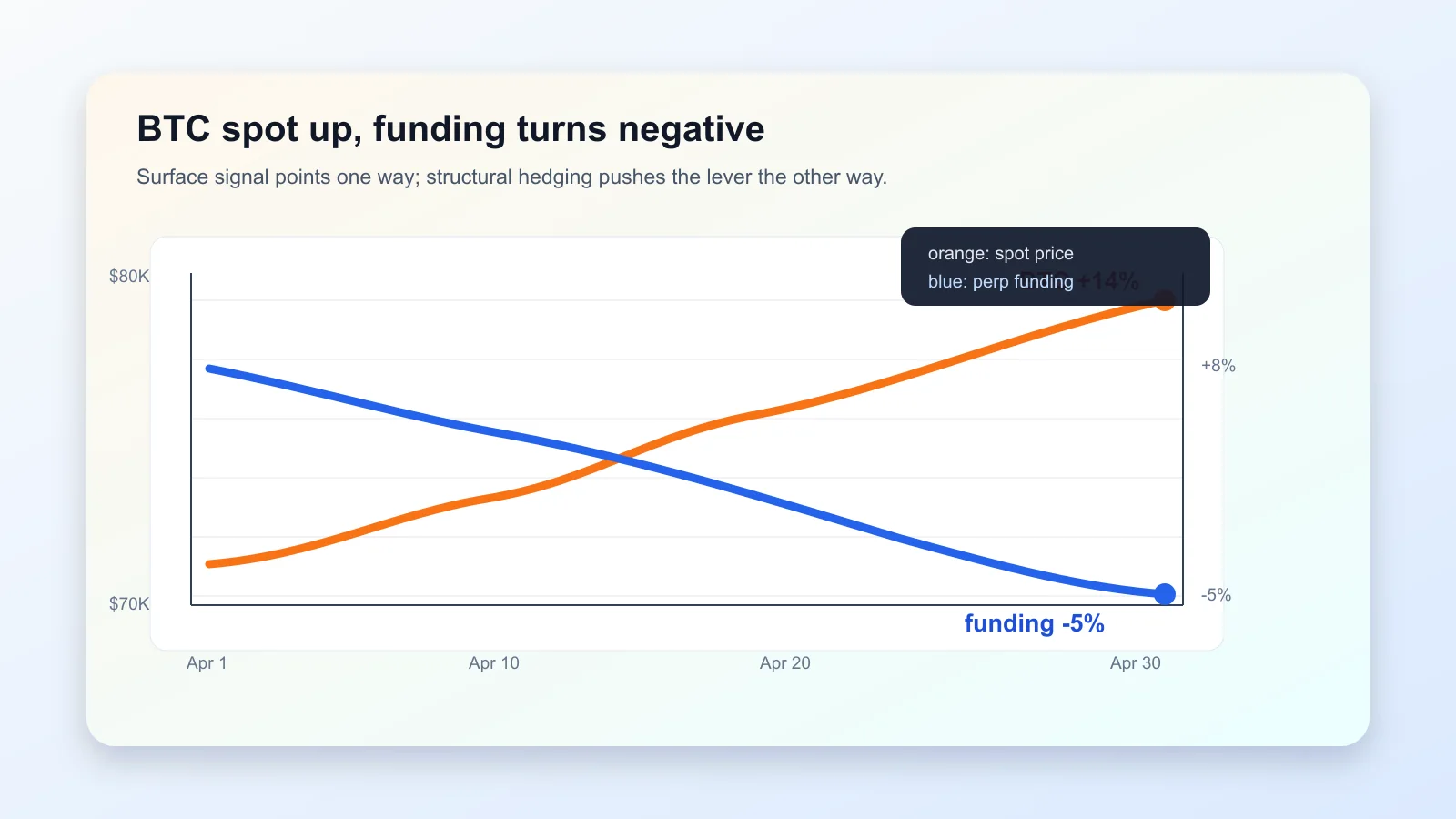
先解释这件事的背景。永续合约(perpetual futures)是加密世界发明的怪东西 —— 一种永不到期的期货。传统期货有交割日,到期时合约价格和现货价格强制收敛;永续合约没有交割日,那怎么不让它们漂走?答案是 funding rate:每 8 小时做一次结算,谁那边偏离现货谁向另一边付钱。正费率 = 多头在抢、付钱给空头;负费率 = 空头在抢、付钱给多头。历史上 BTC 永续 funding rate 的”自然中枢”大约在 +8%(年化)—— 散户喜欢追多,永续天然偏正。
但 4 月这件事就奇怪了。BTC 单月涨 14%(是 2025 年 4 月以来最强一个月),价格逼近 8 万。但 30 天 funding rate 均值 跌到了 -5%,而且越涨越负。
如果你只看表面信号,你的结论会是”市场不相信这次涨、期货在抢做空、回调即将到来”。这个结论是错的,而且错得很有教育意义。
Markus Thielen 在 10x Research 给客户的备忘录里把这次的结构机制拆成三层,每一层都让我心跳慢一拍:
- 一层 · 对冲基金赎回。加密对冲基金过去 5 年累计跑输 BTC 140 个百分点(不是 1.4 倍,是 140%),LP 大量赎回。赎回有通知期,基金在等钱回到银行账户期间,会把组合里的 BTC 风险敞口 用做空永续来对冲掉 —— 这是机械式风控,不是看跌。
- 二层 · MSTR / STRC 套利。Strategy(前 MicroStrategy)4 月一个月内发了 35 亿美元 新债 + 优先股,扩张两条对冲交易:押注 MSTR 股票跑赢 BTC(做空 BTC 永续抵消 BTC 价格风险);收 STRC 优先股 11% 的票息(做空 BTC 永续剥离波动)。两边都要 大量做空 BTC 永续 作对冲腿。
- 三层 · 矿工转 AI。Hut 8 之类的 BTC 矿工自 4 月 6 日起股价涨 48%,因为它们在把矿机算力转去做 AI 推理租赁。买这些矿工股票的基金会同时做空 BTC 永续,把”矿工股 被 BTC 价格干扰”那部分剥掉,留下”矿工股因 AI 转型获得的 alpha”。
Thielen 的原句让人冷静下来:
BTC funding rate 在发出一个不寻常的信号。30 日均值 -5%,对比历史正常值 +8%,BTC 同期涨 15%、期权 skew 在恢复时它还在更负 —— 这是结构在变,不是情绪在变。—— Markus Thielen, 10x Research
这是我能想到的本年度最清晰的”surface vs structure”教材。一边是 funding rate 这个数字(surface signal),另一边是三套机构同时在做的对冲腿(structural cause)。两边方向 完全相反 —— 表面信号说”空头在抢”,机制说”机构正在 进场,做空只是它们进场的副产品”。
这条新闻给我的隐隐然的不舒服,跟我前面讲的 PR-MCI 那个 看起来顺溜的 PR description 是同一种不舒服 —— 当一个数字看起来在告诉你方向,停下来问一句:它为什么这个方向?是因为基本面,还是因为某些不显眼的机制性力量同时在做同一件事? 在永续合约市场,你能问出这个问题就值钱;问不出,你就是给机构对冲腿付小费的人。
我不交易加密。但这个案例我准备放进抽屉,下一次跟人解释”为什么我不相信表面指标”的时候直接拿出来。它比解释 ridge regression 在量化里的作用容易十倍。
五 · 巴黎一只机械手,配一只数据手套

我承认 5 月 6 日那个上午我没第一时间看 Genesis AI 那个发布视频。我当时正在追 Anthropic 的 Code with Claude 直播 —— 同一天,巴黎和加州 San Carlos 那家公司悄悄把视频贴到了 X 上。
我下午看了,看完想关掉再看一遍。
视频里那只人手大小的机械手在 1× 速度(不是慢放)下做的事,按从简单到复杂排:单手剥蛋(壳没碎)、切番茄、做 20 步餐点(包括两手协调做奶昔)、单手 3D 解魔方、实验室级精度的移液和液体转移、钢琴、一只手同时抓 4 个不同大小的物体再分别放进不同箱子、汽车线束(wire harnessing —— 工业机器人多年攻不下的”皱缩、可变形、纤细”任务)。
但机械手不是这个故事最重要的部分。最重要的是配套的那只 触觉感应数据手套。
要解释这只手套有多重要,得先讲背景。具身 AI 过去几年最大的瓶颈不是模型 —— 大型模型现在足够聪明帮机器人决策 —— 而是 数据。机器人要学会一个新动作需要几千到几万次真实演示。过去通过 teleoperation 收集 —— 人穿一套贵到家的设备远程操控机器人手做动作,机器人把这些操作记下来当训练数据。Teleoperation 装备贵、慢、累,每小时高质量数据成本约 200–400 美元。这是机器人行业卡了五年的瓶颈。
Genesis 这只手套是 三件套同时被颠覆:
- 戴上去像戴普通安全手套(实验室和工厂工人本来就戴),轻、不碍事。
- 手套内部映射人手 ↔ 手套 ↔ 机器人手的 1:1:1 关系。你戴着手套正常工作(药企配药、电子厂质检、汽车厂线束、餐厅切菜),手套实时记录力、触感、关节、轨迹。
- 比传统 teleoperation 装备 便宜 100 倍,数据采集效率高 5 倍。
CEO Théophile Gervet(前 Mistral AI 研究员)跟 TechCrunch 说的那句话我抄下来了:“手套最大的价值是 —— 第一次让你能在做日常工作时戴着数据采集设备。”
这是一个非常工程的句子。它的含义是:你不再需要 为机器人示范 —— 你 自己的工作流 就是机器人训练数据生产线。
公司背景值得知道。Genesis 是 2025 年初成立的法国创业公司,1 月做了 $105M seed(和 Mistral AI 并列法国史上最大 seed)。投资人列表里有 Eric Schmidt、Xavier Niel、Khosla Ventures、Bpifrance、MIT 机器人学家 Daniela Rus、计算机视觉研究者 Vladlen Koltun。CEO 是周宪(Zhou Xian),总裁是 Gervet。他们已经在和 法德意 的汽车、电子、制药、物流客户谈合同。合同周期 3–5 年。客户名字暂不公开。
我把这条新闻放进这一刊 —— 七篇里看上去最不搭的一条 —— 是因为它和 Karpathy 第三句话其实是双生子。Karpathy 说招聘要变成”给我一个大项目看你怎么做”,因为算法题是 下一代模型一个 prompt 替掉的水管。Genesis 在更物理的层面说同一件事 —— 机器人 demo 是下一代模型替掉的水管,真正稀缺的是能稳定产生训练数据的物理接口。
接口在哪儿,价值就在哪儿。手套是接口;REPL 是接口;任何 NL-to-something 系统的中间层 schema 也是接口。它们都不在 舞台中央,都不上热搜,但它们决定了未来三年谁手里有数据、谁手里有验证机制、谁手里只是水管。
六 · 12 小时找出一种发光纳米片
这一条新闻不在科技 Twitter 热搜上。我在 Hacker News 上看到一条小链接,点进去看完之后我合上电脑想了五分钟。
北卡州立 + 布朗大学的研究组发的工作叫 PoLARIS(Perovskite Laboratory for Autonomous Reaction Inference and Synthesis)。这是一台 自驱动微流控实验室(self-driving microfluidic lab)—— 你输入”我要找一种特定光致发光特性的双钙钛矿纳米片”,它在 12 小时内自己跑完几百次微反应,找出几组高效配方,顺带还推出来三条之前没人写过的反应路径假说。
要明白这件事有多反常,我必须先解释自驱动实验室是什么。
传统化学实验是”假设 → 配比 → 反应 → 测量 → 论文”,靠人类研究员判断下一步做什么。自驱动实验室是把这个回路 自动化:实验设备自动配比、混合、反应、表征(continuous-flow reactor、in-line spectroscopy),ML 模型读取结果,ML 模型 决定下一个实验配方,设备自动执行下一组。整个 loop 不要人介入。
PoLARIS 选的目标材料叫”双钙钛矿纳米片”—— 是一种 2D 纳米晶体,厚度只有几纳米,光学性质可调,可能用在无铅 LED、太阳能电池、量子点显示。但双钙钛矿配方难在于每片可含最多 6 种元素,每种元素的比例、温度、流速、表面活性剂浓度都影响最终产物 —— 整个搜索空间是几亿种组合。传统方法靠人手一次配一种试,通常几年才出一个好配方。
PoLARIS 做的两件事让它跟之前的自驱动实验室拉开距离:
第一,每个反应单元是一颗流动液滴。微流控反应器一次能跑成百上千颗,每颗液滴是一次独立的微实验。
第二,PoLARIS 不止找”哪个配比效果好”,它还在动态流实验里反推为什么这个配比有效。模型从光谱数据反向推断前驱体反应路径、元素竞争关系,把化学机理写出来。
12 小时内的产出:多组高效双钙钛矿纳米片配方 + 3 条之前没人报道过的反应路径假说。后面这一项是这篇论文的真正分量 —— 它不只是优化器,它是 机理发现器。
这条新闻让我久坐的原因是 —— 化学合成的”配方搜索”和”反应机理理解”过去是两件分开的事。前者用穷举,后者用人类直觉读光谱、看 TEM、写假说。PoLARIS 把它们合一了:在搜索过程里同时让机理 显形。这是把化学家脑子里那个”我猜这反应是因为 X 才发生的”latent state,变成实验输出的一部分。
这个工程姿态对所有做”中间有黑箱”的人都有借鉴价值。你做一个 NL-to-SQL 工具的时候,可以选两条路 —— 让 LLM 端到端从自然语言直接生 SQL(黑箱),或者中间塞一个 可被独立验证的中间 representation(比如 semantic intent spec),这种”中间槽位”让你既能在 SQL 错了的时候定位是哪一步出问题、还能让你单独优化中间表示而不动模型本身。PoLARIS 做的是化学版本的”中间槽位”。两者都拒绝端到端黑箱,都给延迟反馈系统装了一个可观察的中段。
如果你 2026 年下半年要选一个值得追的”AI for science”项目,盯 NC State 的 Milad Abolhasani 实验室、布朗的 Ou Chen 实验室、多伦多的 Acceleration Consortium。它们的工程姿态 —— 写 closed-loop、写决策算法、写自动化 —— 离软件圈日常工作比想象中近。
七 · 海法那几只猫,被 AI 看见了一秒

养过猫的人都知道一个老梗:猫是 面无表情 的动物。狗的脸会笑、会皱眉、会做”内疚 face”;猫的脸像戴了一只面具。这件事我从小信到 2024 年,然后被一篇论文打了脸。
2024 年 11 月,Lyon College 的 Brittany Florkiewicz 和海法大学 Tech4Animals 实验室的 Anna Zamansky 用她们自己训练的 猫脸 AI 识别系统,分析了洛杉矶一家猫咖啡馆 2021–2022 年的 186 段视频(53 只成年短毛猫的社交画面)。
她们想测的是 Rapid Facial Mimicry(RFM,快速面部模仿)—— 当社会性哺乳动物 A 看到 B 做了一个面部表情,A 会在 1 秒之内 无意识复制那个表情。人类有、大猩猩有、马有、狗有 —— 过去被认为是 共情(empathy)的进化前体。问题是猫有吗?没人测过。
结果:猫在友好互动(互相梳毛、蹭头、同卧)下出现 RFM 的频率显著高于敌对场景。模仿最多的部位是 耳朵(FACS 编码 EAD103 和 EAD104)。
这是一篇让”猫是独行动物”的常识被打掉的论文。猫一直在做共情前体动作 —— 只是 人眼太慢、看不见 1 秒内的耳朵微动,所以我们漏掉了 70 年。
本周这一刊的新闻是 —— 同一团队 2026 年 4 月在 Animals 期刊发了续作,把上一篇做的”猫会面部模仿”细化了两个变量:互动场景和性别。结论:
友好场景下两只猫面部表情相似度显著高于中性,敌对场景下显著低(不出意外);公猫之间 的相似度在友好互动里 高于 母猫之间;当一只公猫和一只母猫互动时,公猫倾向于更主动地匹配母猫的表情(不是反过来)。紧张场景下猫倾向于”按类型镜像”(粗略匹配大类),放松场景下倾向于”精确镜像”(细节级匹配)。
这篇论文的方法论亮点比结论更值得品一会儿 —— 她们 没法 用人类评分员标这些数据。人眼看不出 1 秒内的猫耳轻微变化、看不出眼裂宽度的微妙差异。整个研究的数据全部来自训练好的 AI 视觉模型标注。
换句话说,AI 在这里不是被研究的对象,是研究工具本身。是一只显微镜,把人类感知带宽不够的 70 年补回来。
我读这篇论文是 4 月在 X 上看到 Anna Zamansky 的 ResearchGate update。读完我盯着我朋友家那只五岁的奶牛猫看了半小时(她坐在我对面看我吃饭)。我意识到我之前以为的”她在发呆”可能根本不是发呆 —— 她的耳朵在以一秒为单位做我的镜像,而我从来没看见过。
把这件事放进这一刊的真正原因,不是因为它跟 AI agent 有关 —— 它有,但不是主要的 —— 而是它跟前面六篇是同一个故事的 另一个尺度。
猫的社交结构表面看上去稳(“猫是独行动物”),深层早就 isothermal 化了(猫一直在用人眼看不到的频率做共情前体)—— 我们漏掉 70 年,因为我们的感知工具不够快。她们的解法是引入一个 在不同时间尺度上工作的独立观察者(AI)。
这跟 Symbolica 用 REPL 隔出独立上下文、PR-MCI 论文用 23,247 个 PR 把”agent 在说谎”显形、PoLARIS 把化学机理从黑箱里揪出来、Genesis 把工作流变成数据手套 —— 全是同一种动作:当主体的感知带宽不够时,引入一个带宽不同的独立观察者。
下次有人跟你说”AI 抢工作”,你可以反问一句:“AI 还能 看见 你看不见的事,这件事算抢工作还是给工作”?
八 · 一张物理明信片:火焰、晶体、polariton 在同一首诗里
最后一条不那么实用,但很美。
KPZ —— Kardar-Parisi-Zhang —— 是 1986 年三位物理学家写下的一个随机生长方程。它描述的现象很常见也很美:火焰边缘的扩散、晶体表面的逐层生长、培养皿里细菌群落的扩张前沿、烧纸时火苗烧过的边界、湿油漆扩散前沿、咖啡渍干掉时的边缘。
这些现象表面看上去毫不相关。但 KPZ 说:在足够大的空间-时间尺度下,它们的统计涨落 服从同一种标度律 —— 两个特定的关键指数 α 和 β,在所有这些系统里都是同样的值。物理学家管这件事叫 universality,普适性。
KPZ 是 20 世纪非平衡统计物理最深的发现之一,因为它说的是:表面机制完全不同的系统(火焰里的化学反应、晶体里的原子沉积、细菌里的代谢扩散),在足够大的尺度上 被同一个数学骨架支配。
最近五年最让人兴奋的工作是 —— 物理学家在 exciton-polariton condensate(激子-极化激元凝聚态,一种半导体微腔里光和物质的混合量子态)里把 KPZ 在 2 维实验确认了。这件事的重量在哪里?1 维 KPZ 之前在液晶湍流实验里已经确认;但 2 维 KPZ 一直是理论难题 —— 2D 里拓扑缺陷(涡旋)会破坏 KPZ 标度。法国 Grenoble 和 Paris-Saclay 的几个组(Deligiannis、Fontaine、Canet 等)2022 年起在 离散化的 2D polariton 系统里证明了 KPZ 标度可以在 2D 出现,2025 年后续多组实验在持续验证。
我把这件事放在这一刊最后,是因为它像本期所有新闻的一个隐喻。不同系统表面上完全不同 —— agent 运行日志、机器人手、自动实验室、稳定币、诈骗广告、猫脸 mimicry、随机生长界面、雪坡稳定性。但真正高级的阅读姿势,不是记住每个表象,是 识别它们背后的共同语法。
KPZ 提醒我们:世界上很多”看起来乱”的东西,并不是没有结构。只是结构藏在更高一层。当你看到火焰、晶体、polariton 都共享同一个 α 和 β 的时候,你会怀疑你自己每天处理的那些 看似不相干 的工程问题,会不会也共享一个隐藏的标度律。
我个人对跨域类比的偏好可能比一般编辑更重。我倾向于相信:能在金融、政治哲学、生物力学、软件架构之间找到等价物的人,做的事和物理学家在湍流、晶体、polariton 之间找 KPZ 是 同一种动作,只是尺度不同。这是一种 经验性的 universality 直觉。如果你也有这个倾向,KPZ 这一条算是给你的一张物理明信片。
编后 · Dragon’s Tail Couloir,5 月 6 日下午三点

5 月 6 日下午三点 —— 也就是 Anthropic 在旧金山主舞台开始演讲、Genesis AI 在巴黎发机械手、Symbolica 在 GitHub commit 的同一天 —— 落基山国家公园北坡 Dragon’s Tail Couloir,海拔 3,750 米,两位滑雪者上到 couloir 下三分之一处开始穿装备。雪坡释放了一次湿板雪崩。第一位停在表面,第二位被冲过一个小崖带,落地时头盔凹了一块、嘴唇撕开。两人都自行走了出来。
这是体育新闻。让我停下来的是 CAIC(Colorado Avalanche Information Center)事故后追加的那段技术解释:
在 Colorado 五月发出 Level 4(高危)警告是罕见的。原因是前一周一次晚季暴风雪在已有的春季湿雪 snowpack 上面堆了几英尺新干雪。新干雪和老湿雪之间形成了一个高度不稳定的弱层。新干雪本身没问题,老湿雪本身已经稳定下沉了 —— 问题是它们之间的那一道界面。—— CAIC
要懂这段话,得知道 isothermal 是什么意思。雪学里 isothermal(等温)指雪层全部到 0 °C 那一刻,雪粒间的固态键合开始失效。Colorado 这个雪季整体 snowpack 比往年薄很多,3 月底又出现破纪录的持续暖期,整个 snowpack 在 3 月 18 日之后就开始等温化进程。
到了 4 月、5 月,表面温度下降,雪坡 看上去 又稳了 —— 风干表层、夜间冻结、白天慢融慢冻 —— 但 深层的 weak layer 没有消失,只是被冬天最后一波新雪盖住了。新雪盖 + 老 weak layer + 春日午后日照 = 湿板释放。
把这件事翻译成抽象语言:
雪坡是一个延迟反馈系统。3 月暖期的破坏不在 3 月显形,而是被 4 月新雪埋起来、在 5 月某个温暖的下午三点释放。表层稳定信号(“上面冻得好硬”)和深层结构信号(“weak layer 还在那”)解耦。
这一刊每一条新闻都是这同一个故事的某个变奏。Symbolica 350 行解决的是 上下文窗口塞太多就会塌 —— 表面看 LLM 在好好工作,深层只有 5% 的 attention 在处理你的真问题。PR-MCI 揭示的是 PR description 看上去靠谱,diff 里没东西。HAL 揭示的是 reasoning token 越多看上去越深,实际越差。Karpathy 的 MenuGen test 是 你的 app 现在跑得好好的,但下一代模型一个 prompt 就吞掉你。BTC funding rate -5% 是表面信号和结构机制方向相反。Genesis AI 是机器人 demo 看着惊艳,但真正稀缺的是能稳定产生训练数据的物理接口。PoLARIS 是化学合成的”配方好”和”机理理解”过去是两件事 —— 自驱动实验室把它们合一显形。海法那些猫是 看似独行,1 秒级共情,漏掉 70 年。KPZ 是表面机制不同的系统在深层服从同一标度律。
九件事都是 延迟系统的早期警报问题。问题不是”现在没事”;问题是”我能不能在我看到事的时候,重新构造 出系统的隐藏状态、判断它是不是在 isothermal 化的路径上”。
我相信 2026 年下半年很多公司的工程岗 JD 会越来越多出现一个词 —— observability。它不是新概念(DevOps 圈用了十几年),但 agent 时代它会被 重新定义 成一个更深的东西:不只是”我看见这个服务挂了”,而是 “我看见我以为这个 agent 做对的那件事 实际 没做”。
如果你今晚要带一句话回家,让它是这样的:
当系统变复杂时,外化你不能控制的(用独立 grader 隔出判断),同时显形你看不见的(用 schema、用 REPL 隔层、用 AI 视觉、用闭环实验、用数据手套、用雪坑探测 —— 让中间状态可观测)。这是 2026 年值得追的所有事的共同语法。
下下刊我会盯五条:Symbolica/Agentica 在实际生产环境的 fork 反馈、Karpathy 第三句话引发的招聘流程变化、HAL 的 reliability 第二份报告、自驱动实验室向制药领域扩张的第一篇 Nature 系列论文、Genesis AI 第一个公开签约车厂。也可能会捎带一条 ARC-AGI-3 的 6 月新 SOTA,如果 imbue 或 Symbolica 那边有动静。
外面阳台上有一只两个多月大的小家伙正在认真研究怎么把咖啡豆碾平。他不知道海法和 Lyon College 已经为他每一次耳朵的轻微转动建立了 AI 量化模型;不知道在 350 行 Python 里有人用和他一样的”递归探索”策略干掉了 ARC-AGI-2;不知道科罗拉多某条 couloir 在他出生那天就 isothermal 化、五月才释放;不知道巴黎一只机械手在 1x 速度下完成了 20 步烹饪。
也好。让他玩。
—— 编辑
评论